
Geçtiğimiz hafta İngiltere merkezli The Guardian gazetesinde yayımlanan bir haber, Harvard Tıp Fakültesi’nden bir grup araştırmacının ilginç çalışmalarını ele alıyordu. Bu çalışma, OpenAI’ın iki farklı dil modeli olan o1 ve ChatGPT 4 ile uzman ve asistan hekimlerin tıbbi konulardaki yetkinliklerini iki farklı senaryoda karşılaştırıyordu.
Araştırmanın ilk bölümünde, tıp alanında önemli bir dergi olan New England Journal Medicine (NEJM) tarafından düzenlenen tarihi klinik vaka konferansları, sanal hasta senaryoları ve uzman hekimlerce hazırlanmış tedavi planlaması gibi beş farklı simülasyon ortamında dil modelleri ile doktorlar karşılaştırılmış. Sonuçlar, tüm kategorilerde dil modellerinin, doktorların üzerindeki performansının daha yüksek olduğunu ortaya koymuş.
İkinci bölüm ise Boston’daki bir hastanenin acil servisinden rastgele seçilen 76 hastanın tıbbi geçmişine odaklanmış. Hem doktorlara hem de dil modellerine hastalara ait aynı elektronik kayıtlar verilmiş ve ilk triyajda dil modellerinin %67, doktorların ise %50-55 oranında doğru teşhis koyduğu belirlenmiş.
The Guardian’daki haberde, özellikle bu ikinci bölüm vurgulanarak yapay zekânın doktorlardan daha iyi performans gösterdiği iddia edilmiş. Bu başlık, güncel hype ortamına uygun bir şekilde dikkat çekmiş ve X platformunda Türkçe ve İngilizce hesaplarca paylaşılmış.
Bu noktada, bahsedilen çalışma sonuçlarının gerçek hayatta ne kadar geçerli olduğunu sorgulamak önemli. Çalışmanın senaryoları, gerçek hayattaki karmaşık durumlardan uzak bir yapıya sahip. Önceki yazılarda belirttiğim gibi, bu modeller “ideal” koşullarda belirli girdilere dayalı olarak iyi sonuçlar veriyor. Ancak gerçek yaşamda, öğrendikleri örüntülerin dışında bir durumla karşılaştıklarında çoğu zaman başarısız olabiliyorlar. Bu durumu destekleyen çok sayıda literatür bulmak mümkün. Araştırmacılar da bu handikapın farkında.
Çalışmanın kıdemli ortak yazarlarından Raj Manrai, X platformunda yaptığı açıklamada bulguların çağrısını net bir şekilde ortaya koyuyor. Manrai, bu sonuçların prospektif klinik deneylerin yapılması, sağlık sistemlerinin altyapısına yatırım yapılması ve sadece tanı doğruluğuna odaklanmadan güvenlik, verimlilik ve maliyet gibi unsurları da izleyen denetim çerçeveleri geliştirilmesi gerektiğini vurguluyor. Yani, çalışmanın yazarı bile bulguları tek başına yapay zekânın doktorların önüne geçtiği şeklinde yorumlamıyor.
Bu çalışmayı, alanında otorite kabul edilen Amerikan kardiyolog Eric Topol’un gözünden değerlendirmek de faydalı. Topol, bu çalışmayı değerlendirirken, deneylerin tamamının hasta vakası vinyetleri, simülasyonlar ve hasta rolündeki aktörler üzerinden gerçekleştirildiğini belirtiyor. Gerçek hekimlik pratiğinin “düzensiz, dağınık” doğasını temsil etmeyen bir ortamda yapıldığını ifade eden Topol, bu nedenle bulguların “potansiyel” olarak değerlendirilmesi gerektiğini, gerçek hayatta doktorların yerini alabileceğine dair kesin bir kanıt sunmadığını aktarıyor.
Gerçek dünyadaki durum ise farklılık gösteriyor. Nature Medicine’de yayımlanan bir başka çalışma, ChatGPT’nin hastaları evde mi kalmaları yoksa acile mi gitmeleri gerektiği konusunda triyaj etmesini test etmiş ve sonuç olarak ChatGPT’nin ciddi teşhis hataları yaptığı görülmüştür. Ayrıca, başka bir randomize çalışmada on farklı tıbbi senaryoda hastaların büyük dil modelleri ile aldıkları kararlar değerlendirilmiş ve hastaların performansı düşük çıkmıştır. Yazarlar, makaleyi sistematik insan testlerinin sağlık sektöründe uygulanmadan önce zorunlu olduğuna dair bir uyarı ile sonlandırmıştır.
Hastanın yapay zekâya aktardığı bilginin kalitesi de önemli bir faktör. Geçtiğimiz günlerde yayımlanan bir çalışma, hastaların belirtilerini yapay zekâya aktardıklarında, bunu bir doktora tarif ettiklerine kıyasla daha az ayrıntılı ve kalitesiz bilgi paylaştıklarını ortaya koyuyor. Bu durum, modelin çıktısının gerçek başarısını tek başına yansıtmadığını gösteriyor; çünkü modelin önüne konulan girdiler, hekim muayenesi sırasında sağlanan bilgi zenginliğinden uzak kalıyor.
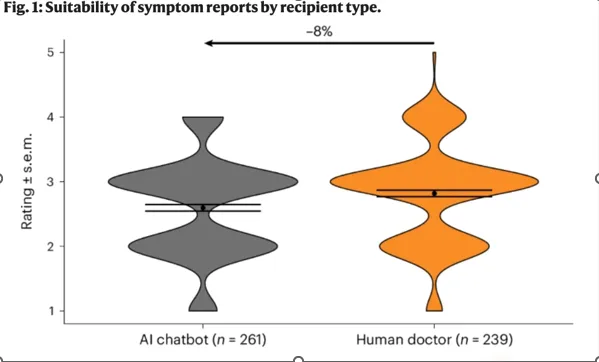 Figür 1: İnsanlar bir AI chatbotla konuştuklarını düşündüklerinde semptomlarını %8 daha az ayrıntılı aktarıyor.
Figür 1: İnsanlar bir AI chatbotla konuştuklarını düşündüklerinde semptomlarını %8 daha az ayrıntılı aktarıyor.
Buraya kadar yazılanların, aslında aynı meseleyi farklı yönlerden ele aldığını görmek mümkün. Dil modelleri, kontrollü laboratuvar koşullarında, özenle hazırlanmış vakalar üzerinde doktorların önüne geçebiliyor. Ancak tıp pratiği sadece bu kontrollü ortamlardan ibaret değil. Hasta, net bir vinyet değil; eksik bilgi veren, yanlış hatırlayan, çelişkili belirtiler sunan bir insandır. Acil servisteki triyaj kararı da yalnızca elektronik kayıtların okunmasından ibaret değildir; hastayla göz teması, refakatçinin yorumu, anlık fizik bulgular gibi modele aktarılması imkânsız sinyaller de bu kararın bir parçasıdır.
Yapay zekânın tıp dünyasındaki etkileri yalnızca dil modelleri ile sınırlı değil. Geçtiğimiz hafta “Yapay Gündemler” isimli bültenimde, radyoloji alanında benzer bir tabloyu ele almıştım. Yapay zekânın öncülerinden Geoffrey Hinton, on yıl önce radyolojistlerin eğitimini durdurmamız gerektiğini, beş yıl içinde modellerin tıbbi görüntülerde insanları geçeceğini belirtmişti. Ancak aradan geçen on yıl içinde Amerika’daki radyolojist sayısının artmaya devam ettiğini gösteren veriler var. Hatta ChatGPT’nin yaygınlaştığı 2022 sonrasında bile bu artışta bir kesinti yaşanmamıştır. Ortalama yıllık gelir 500.000 dolara yükselmiş durumda ve FDA, radyoloji alanında 700’den fazla modelin kullanımına onay vermiştir. Amerika’daki radyolojistlerin %48’i bu modelleri aktif olarak kullanıyor, ancak yine de radyolog ihtiyacı artmaktadır.
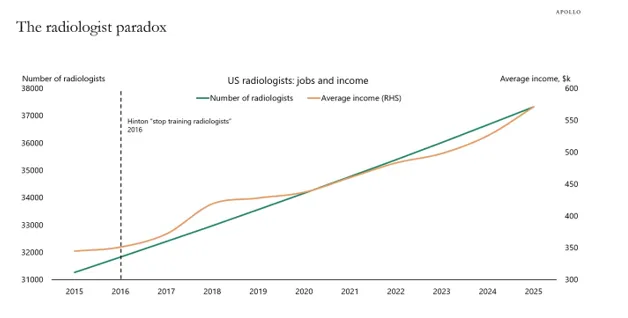 Figür 2: Amerika’daki radyolojist sayısının zaman içindeki değişimi.
Figür 2: Amerika’daki radyolojist sayısının zaman içindeki değişimi.
Bu durumun arkasında, modellerin gerçek dünyada nasıl davrandıklarıyla ilgili bir paradoks yatıyor. Görüntü işleme modelleri, eğitim verisinden farklı bir hastane verisiyle karşılaştıklarında başarı oranları %20 oranında düşmektedir. BMJ’de yayımlanan başka bir çalışma, en gelişmiş görüntü işleme modellerinin bile kendi başlarına bırakıldıklarında aşırı tanı eğilimleri gösterdiğini ortaya koymuş. Bu da hem operasyonel maliyetleri hem de hasta sağlığını riske atan müdahalelere neden olabiliyor. Radyolojistlerin çalışma zamanlarının yalnızca %36’sı görüntü yorumlamaya ayrılırken, geri kalan zaman hastayla iletişim, asistan eğitimi, etik ve hukuki süreçler gibi alanlara harcanmaktadır.
Bir başka önemli durum ise, Topol’un Ground Truths bülteninde belirttiği gibi,





Yorumlar kapalı.